 Projekte Projekte
|
| Team |
Peter Heilbronn |
| Thema |
Beschreibung des internen XML-Formates
( original )
|
| Letzte Bearbeitung |
06/2006 |
| Home |
www.mxks.de
|
1. Allgemein
1.1. Warum XML?
1.2. Technischer Kontext - XSL, ANT und Java
1.3. Dateien im Netz
1.4. Verschlüsselung im Netz
2. Die XML-Dokumentbeschreibung
2.1. Ausgangspunkt - das Exzerpt
2.2. Was das Format nicht ist!
2.3. Was ist ein Tag?
2.4. Das Zitat - Cite
2.4.1. Feste Nummerierung der Fußnote
2.4.2. Auslassungen im Zitat - CBr und CDot
2.4.3. Hervorhebung im Zitat - Cite/@em
2.4.4. Verwendung des Zitatkataloges - CiteCatalog(Ref)
2.4.4.1. Fortlaufende Fußnoten - @style=''strict''
2.4.4.2. Nur Quellenauflistung - @style=''compact''
2.5. Internes Zitat - cite
2.6. Absatz - P und PP
2.7. Seitenbemerkung - CommentHead
2.8. Kommentar - Comment
2.9. Fußnote - Footnote
2.9.1. Feste Nummerierung - vorgegebenes Dokument
2.9.2. Automatische Nummerierung - eigenes Dokument
2.10. Seitenfuß - Pagefoot
2.11. Wichtiger Punkt - CardinalPoint
2.12. Dokumentbeschreibung - Abstract
2.12.1. Abstract/@type=''excerpt''
2.12.2. Abstract/@type=''original''
2.12.3. Langer Zusatz- oder Informationstext - Abstract/P|Cite
2.12.4. Kurzer Zusatz- oder Informationstext - Abstract/@desctiption
2.13. Dokument
2.13.1. Sichten - Struktur
2.13.2. Conspectus - Konspekt als ''innere'' oder eigene Datei
2.13.3. Originale und innere Verlinkung
2.13.4. Baumstruktur eines Dokuments
2.14. Kapitel und Unterkapitel - Section, Subsection
a.) Nummerierung
2.15. Seitenangabe - Page
2.16. HTML-Tags
2.17. Bild - img
2.18. Entities
2.19. Links - Ref
3. Ansehen von XML ohne Compiler
3.1. Entpacken und Test
3.2. Eigene Datei vorbereiten
3.3. Erklärung
4. Die interne Struktur
4.1. Übersicht und Technisches
4.2. Das XML-Projekt
4.3. ANT-Buildfiles
4.3.1. Environement - Umgebungsvariable
4.3.2. Pfade
4.3.3. xmlcatalog
4.4. Strukturfile oder Navigationsfile - mxks/main.navbar.xml
4.4.1. NavGroup - Ebene
4.4.2. NavItem - Einzelseite
4.4.3. NavGroup - Automatismus
4.5. Indexfiles - Automatismus
4.5.1. IndexGroup
4.5.2. IndexItem - Exzerpte
4.5.3. DocInfo - Konspekt, Struktur, Bilder, ...
4.5.4. IndexItem/@style
4.5.5. Tabellarische IndexGroup - @type='multicolumn'
4.5.6. IndexGroupRef - Referenz zu externer Indexdatei
4.5.7. IndexItemRef
4.6. Stylesheets
4.6.1. html
4.6.2. navbar
4.6.3. css
4.6.4. index
4.6.5. excerpt
4.6.6. Nicht-Indexseiten oder reine Datenseiten
5. Erzeugen von ANT-Build-Files mit XSL
1. Allgemein
1.1. Warum XML?
Um die Webseiten und alle möglichen anderen Dokumente automatisch erstellen zu
können, haben wir uns entschieden, alle Informationen, Texte und Beschreibungen
in XML zu machen. Das hat den entscheidenden Vorteil, dass man mit einer Unmenge
von schon hoch standardisierten Werkzeugen auf der gesamten Datenmenge operieren
kann. Alle Dokumente werden als eine Art Datenbank benutzt.
Viele abhängige Dokumente, wie z.B. Newsletter oder verschiedene Gruppierungen
auf unterschiedlichen Navigationsseiten der gleichen Daten, kann man mit einem
Mindestmaß an Redundanz erzeugen. So steht z.B. die Kurzbeschreibung eines
Textes nur in diesem Text selbst (so es ein XML-File nach unserer Beschreibung
ist).
Überall nun, wo diese Beschreibung benötigt wird, sie anzuzeigen, wird sie aus
dem Dokument selbst genommen. Ändere ich diese, so muss ich nicht überlegen, wo
ich überall diese Änderungen noch machen muss, sondern ich übersetze einfach
alles neu. Einmal schreiben, überall sehen.
Da mir alle vorhandenen Formate zu kompliziert oder auch zu
allgemein schienen, habe ich mich entschieden, eigene
Minimal-DTD's zu erstellen. Sie sind so einfach gehalten, dass man im
Zweifelsfall
sehr schnell eine Umsetzung in ein anderes Format vornehmen kann.
Allgemeines zu XML/XSL findet man beim
W3C bzw. eine
hervorragende
Einführung mit Beispielen und verständlicher Beschreibung bei
Selfhtml, dass ich an
dieser
Stelle nicht darauf eingehen möchte. Jeder, der sich mit HTML auskennt,
kann sehr
schnell zurecht kommen. XML ist,
was du beschreiben willst, mach eckige
Klammern drum.
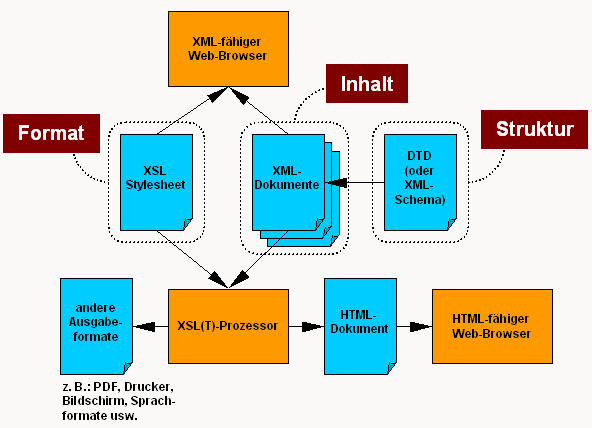
Hier wird der grundsätzliche Vorgang beim Übersetzen mittels XSL
gezeigt.
Groß und Kleinschreibweise wird beachtet!
Das Format und seine Anwendungen unterliegen einer ständigen Veränderung und
sind so zusagen als Baustelle zu betrachten.
Als Beispiel dieses Dokument in seiner
XML-Form. Das sieht
sehr schrecklich aus,
aber wenn man es sich in seinem browser als Quelltext ansieht, dann wird die
Struktur ersichtlich.
1.2. Technischer Kontext - XSL, ANT und Java
Haben wir die Daten, die Beschreibungen und die Definition der Struktur der
ganzen Webseite nun in der gleichen(!) Form - XML - gemacht. Dann wollen wir
natürlich unsere Webseiten daraus erstellen. Hier haben wir uns für die
Grundtechnologie XSL entschieden.
Die XSL-Stylesheets, die die Umsetzung von XML zu z.B. HTML vornehmen, sind
selbst in XML geschrieben und könnten so sich selbst modifizieren. (Machen wir
im Augenblick nicht.) Aber sie sind flexibel genug, um das zu tun, was wir
wollen.
Jetzt kennen wir die Datenbeschreibung (XML), die Übersetzungssprache (XSL) und
nun brauchen wir noch eine Software-Maschine, die die Umsetzung auch vollzieht.
Die Entscheidung fiel zu Gunsten des Werkzeugs ANT. ANT wird an Hand von
sogenannten Build-Files gesteuert, die selbst wieder in XML geschrieben sind.
Das wird massiv benutzt, indem wir automatisch neue Build-Files erzeugen um
automatisiert abhängige Webseiten von Webseiten zu erzeugen. In den Build-Files
selbst kann man ANT wieder neu anstarten und fertig ist eine Kaskadierung von
Übersetzungsvorgängen.
Es ist also einerseits, dass ANT über XML-Dateien gesteuert wird. Andererseits
ist es ein kleines kompaktes Werkzeug, was aber eine Unzahl von schon
vorhandenen Schnittstellen und Prozessen bietet, die wir also nicht extern noch
anfügen müssen. Als Wichtigstes für uns ist der XSL-Prozessor schon mit dabei!
Wir können also XSL compilieren, als auch Dateioperationen vornehmen, z.B.
kopieren, packen oder löschen. Damit haben wir nun alles, um automatisch eine
ganze Webseite erzeugen zu können mit minimalstem technischen Aufwand. Was
natürlich damit erkauft wird, dass man sich mit den Technologien XML/XSL/ANT
relativ gut auskennen muss.
Konkret baucht man im Wesentlichen eine relativ neue
Java-Runtime, weil ANT in Java
programmiert ist und das Werkzeug
ANT selbst. Das wäre auch schon alles.
Aktuell wird zum Übersetzen der Seiten ANT mit verschiedenen Parametern
(eigentlich nur der Name des ANT-Targets)
direkt über die Kommandozeile aufgerufen.
1.3. Dateien im Netz
Im Netz befinden sich folgende Dateien, die man benötigen wird
- Die DTD's für unsere Seiten sind hier öffentlich zugänglich:
http://www.mxks.de/dtd/XXXXX.dtd.
- Das Paket, um sich eigene XML-Exzerpte zu Hause anzusehen, ist hier XML-Paket zu finden.
1.4. Verschlüsselung im Netz
Man braucht erstens ein Programm wie
PGP,
GnuPG oder
ein anderes public key privacy Programm. Damit geht es schon, ist aber
umständlich.
Zweitens ist ein Mailprogramm gut, in welches man dieses PGP fest einbinden
kann. Unter Linux nehme ich KMail + GnuPG.
Damit kann man
- Mails verschlüsseln
- Mail unterzeichnen, damit ihr Inhalt nicht verändert werden kann und
der Absender relativ sicher ist.
Das Vorgehen ist in den Hilfefiles der einzelnen Programme meist sehr gut
beschrieben. Auch kann man eine Menge mehr nützliche Dinge damit treiben.
Jeder Nutzer hat ein Schlüsselpaar, einen öffentlichen und einen geheimen
Schlssel genannt public und secret key. Diese sind in den jeweiligen Files
genannt Schlüsselbund oder key ring zusammengefasst.
Ihr verschlüsselt eine Nachricht mit EUREM secret key und dem public key des
oder der EMPFÄNGER[S].
Er entschlüsselt mit EUREM public key und SEINEM/IHREM secret key.
Deshalb hängt an meiner Mail mein public key. Wenn ihr mir euren schickt,
dann können wir PGP so zusammen nutzen und den Schlapphüten die Arbeit
etwas erschweren. Diese Mail ist außerdem unterschrieben, um den wahren
Absender und den Inhalt zu schützen.
2. Die XML-Dokumentbeschreibung
In diesem Kapitel wird beschrieben, wie eine Datei in XML geschrieben werden
muss, damit mit unserem System als XML-Dokument automatisch in die gesamte
Übersetzung eingepasst wird. Natürlich ist es auch möglich Dokumente jeder Art
einfach über einen Link von jeder Seite aus erreichbar zu machen. Aber damit
verliert man gerade den Vorteil des Automatismus.
2.1. Ausgangspunkt - das Exzerpt
Ausgangspunkt des ganzen Projektes waren Exzerpte, also wissenschaftliche
Texte, die wir in verschiedenen Weise unter verschiedenen Gesichtspunkten
dargestellt und verlinkt haben wollten. Z.B. eine HTML-Seite für den normalen
Text (Exzerpt), eine für die Zusammenfassung (Konspekt), einen für die Struktur
der Bearbeitung (Struktur) und die Möglichkeit das Ausgangsmaterial mit
anzuhängen (Original) oder Zusatzpakete (Info).
Dabei wollten wir möglichst jede Information nur einmal schreiben und
verschiedene Sichten auf die selben Daten generieren, bzw. diese Exzerpte von
verschieden gruppierten Indexseiten aus erreichen können. Jedesmal den
HTML-Code von Hand zu schreiben und bei Designänderungen, die nicht nur z.B.
über CSS zu behandeln sind, alle betroffenen Seiten zu bearbeiten und keine zu
vergessen, dass schien irgendwann zu öde und fehleranfällig.
2.2. Was das Format nicht ist!
Unser Format ersetzt nicht die übermächtigen Textformatierungen von moderner
Textverarbeitung, aus der man im Allgemeinen auch nach HTML exportieren kann.
Schon gar nicht ersetzt es naturwissenschaftliche Dokumentformatierung wie
LaTEX. Darum geht es auch gar nicht.
Es ist gerade ein Vorteil, das man hier nur sehr wenige Tags lernen muss, die
im Wesentlichen den Tags von HTML selbst entsprechen. Es ging um
(wissenschaftliche) Fließtexte ohne Formeln, die eben genau mit der Formatierung
auskommen, die hier umgesetzt worden ist (Obwohl man ja einfach z.B. MATHML
benutzen kann.) Es ist aber auch kein Problem, weitere Tags zu definieren und in
DTD und XSL einzubauen.
2.3. Was ist ein Tag?
Ein Tag ist eine Beschreibung, bzw. Markierung, seines Inhaltes.
Der 'Cite'-Tag sagt an, dass alles, was in ihm steht, ein Zitat ist und als
Zitat dargestellt werden soll. XML-Dokumente sind so gesehen nichts anderes
als verschachtelte Tags, in welche man den eigentlichen Inhalt plaziert. Das
ist das Gleiche wie bei HTML, wenn auch flexibler und strenger.
Technisch gesehen ist ein Tag von der Form:
<TAGNAME>
Inhalt des Tags, das können Text oder weitere Tags sein.
</TAGNAME>
Also was ich sagen will, das kommt in spitzte Klammern. Der zweite Tag-Teil
sagt an, wann
der Inhalt, der z.B. als Zitat beschrieben wurde, zu Ende ist. Fehlt dieser
Abschlussteil, so ist das Dokument nicht wohlgeformt und wird nicht
verarbeitet.
Tags können nur vollständig in einander geschachtelt werden und
dürfen sich nicht
überlappen! Es gibt auch leere Tags, d. h. solche, die keinen Inhalt
haben. Das
sind dann meistens reine Formatierungs-Tags wie z.B. 'Zeilenumbruch'
<br />. Diese haben eine zweite spezielle Kurzschreibweise <TAGNAME
/> und besitzen keinen Abschluss-Tag. Diese Kurzschreibweise ist das gleiche
wie <TAGNAME></TAGNAME> - also ohne Inhalt.
Tags haben auch sogenannte Attribute oder Eigenschaften, wie zum Beispiel
vom
Zitat die Seitennnummer und die Quelle des Zitats. Eigenschaften können
notwendig oder auch optional (nicht notwendig) sein. Im Folgenden bezeichnet
'*' ein Stern hinter dem Namen ein notwendiges
Attribut. Dieser Stern ist dann aber nicht als Attributname anzugeben!
Die Attribute eines Tags werden formal im Text angegeben in der Art
TAGNAME/@ATTRIBUTNAME. Untertags werden formal angegeben
OBERTAGNAME/UNTERTAGNAME. Ein
Untertag ist ein Tag, der in einem anderen Tag, Obertag genannt wird,
eingeschlossen ist. Die heißt auch er ist verschachtelt.
<Obertag>
<Untertag attribut1="value1" >
...
</Untertag>
</Obertag>
Das Attribut wird somit angegeben:
Obertag/Untertag/@attribut1="value1". Diese Art der Beschreibung
nennt sich auch XPath und kann als Bestandteil von XML angesehen werden.
Mit Hilfe dieses Formalismus lassen sich alle möglichen Tags und ihre
Attribute
in einem Dokument adressieren, wobei noch viele andere Mechanismen hierfür
benutzt werden.
2.4. Das Zitat - Cite
Der erste Tag, den wir uns ansehen, ist Cite - ein Zitat. Der Inhalt, also
alles das, was zwischen Anfangstag <Cite> und Endtag </Cite> steht,
wird als Text des Zitats betrachtet.
Dann gibt es noch diverse Nebeninformationen, die am Zitat hängen, wie die
Quellenangabe (z.B. Werkstitel und Seite) oder eine zugehörige Fußnote.
Auslassungen müssen gekennzeichnet werden, sowie eigene Hervorhebungen. Das
werden wir uns nun ansehen in seiner technischen Umsetzung.
2.4.1. Feste Nummerierung der Fußnote
Betrachten wir zuerst das Zitieren mit jeweiliger textueller Angabe der Quelle
über das Attribut @src und der Zählen Nummerierung der
zugehörigen Fußnoten.
<Cite src="die Quelle" page="die Seitennummer" footnote="Nummer der
Fußnote">
das Zitat
</Cite>
Also sind 'src','page' und 'footnote' optionale Attribute, da sie nicht mit
einem Stern * gekennzeichnet sind.
So sieht es dann aus:
"
Dies ist ein Zitat.
Dies ist ein Zitat.
Dies ist ein Zitat.
Dies ist ein Zitat.
"
(Quelle, S. 23)
Es ist zu beachten, dass die angegebene Nummer der Fußnote für den Modus des
Zählens von Fußnoten benutzt wird. Beim automatischen Zählen
wird mittels des Zitatkataloges automatisch eine entsprechende Fußnote
kreiert, die als Zitatnachweis im Anhang aufgeführt werden kann.
2.4.2. Auslassungen im Zitat - CBr und CDot
Wenn man in einem Zitat Auslassungen hat, sollte man, anstatt die Punkte
im Code zu machen, den CBr-Tag oder
CDot verwenden. Oftmals
gibt es verschiedene Vorgaben für die Formalien und so ist es besser,
einem zentralen angepassten XSL-Stylesheet die Darstellung zu überlassen.
"
Hier machen wir jetzt eine Auslassung mit <CDot /> und das sieht ...
aus. Oder wir haben eine längere Auslassung
...
machen dafür den Cite Break <CBr /> und fahren fort zu zitieren.
"
2.4.3. Hervorhebung im Zitat - Cite/@em
Oftmals sind in Zitaten Hervorhebungen des Autors selbst, und man will aber auch
eigene Hervorhebungen machen. Im Augenblick sind die des Autors als
<i>kursiv</i>
gekennzeichnet und damit nicht sichtbar, da das Zitat selbst in HTML in Gänze
kursiv gesetzt ist. Der Tag für das Kursivsetzen ist in HTML der
Italic-Tag, daher das 'i'.
Eigene Hervorhebungen sollten mit dem Bold-Tag, d. h.
<b>Fettschrift</b> gekennzeichnet sein, mit dem Hinweis
'[Herv. v. XXX]'.
Das Zitat hat ein weiteres Attribut bekommen @em. Damit wird
gesagt, dass im Zitat eigene Hervorhebungen sind. Da dies auch verschiedenen
Formalien unterliegt, wurde die Darstellung dieser Angabe auch dem zentralen
Stylesheet überlassen.
"
In diesem Zitat hat das em-Attribut den Wert 'XXXX' und dieser ist der Name
oder das Kürzel desjenigen, welcher die Hervorhebung oder auch
Emphase genannt macht.
"
[Herv. v. XXXX]
2.4.4. Verwendung des Zitatkataloges - CiteCatalog(Ref)
Den Zitatkatalog kann man einfach als komfortable Aufzählung der zitierten
Werke verwenden.
Die zweite Möglichkeit ist, pro Zitat oder automatischer Fußnote
eine Fußnote in der Reihenfolge wie im Quelltext fortaufend erzeugen zu
lassen.
Der Zitatkatalog
CiteCatalog enthält die Beschreibung
für in Zitaten verwendete
Literatur. Pro Werk existiert genau ein
CiteCatalogItem,
welches ein
Abstract enthält, mit der vollständigen
Beschreibung. Jeder dieser Einträge enthlt notwendigerweise eine
im Zitatkatalog eindeutige Zeichenkette als Identifikation und Referenz, das
Attribut
@cid.
- CiteCatalog
- CiteCatalogItem cid="Referenzzeichenkette"
- Abstract author="Nachname" title="Titel" ...
- ...
- CiteCatalogItem
Der Katalog sollte möglichst am Anfang oder am Ende in das XML-Dokument
eingefügt werden. Ebenso darf nur
ein einziger Katalog-Tag existieren
pro XML-Dokument.
Hier nun unser Testkatalog.
<CiteCatalog">
<CiteCatalogItem cid="nudel"">
<Abstract
authorsfirst="First"
author="Name"
title="Der Titel des Werkes"
edition="2.Aufl."
date="1840"
location="Zumbelstadt"
volume="Band 2"
/">
</CiteCatalogItem">
<CiteCatalogItem cid="popo"">
<Abstract
authorsfirst="First"
author="Name"
title="Der Titel des zweiten Werkes"
/">
</CiteCatalogItem">
</CiteCatalog">
Infolge sind ein paar Zitate definiert, mit welchem die Wirkungsweise deutlich
gemacht werden soll. Die Zitate benutzen anstatt dem Attribut @src, in welchem
die Quelle textuell angegeben wird einen Verweis in den Zitatkatalog, um die
Quelle zu bestimmen. Dieses Attribut heißt @cref und korrespondiert dem
@cid der ausgewählten Zitatquelle.
<Cite cref="Verweiskürzel" page="Nummer der
Seite">
das Zitat
</Cite>
{
Im Gegensatz zum festen Nummerieren gibt es noch keine Möglichkein, einen
weiteren Fußnotentext außer der Quellenangabe zu kreieren.
(d.V.)}
Ein @cref-Eintrag muss im Katalog eindeutig sein. In
unserem Falle
verwenden wir die Kürzel "nudel" und "popo" als die Einträge.
<Cite cref="nudel" em="P.H." page="5f">
Der Inhalt des Zitates mit Hervorhebung '@em="P.H."' und Seitenangabe
'@page="5f"'
</Cite>
<Cite cref="popo">
Der Inhalt des Zitates
</Cite>
<Cite cref="nudel">
Der Inhalt des Zitates
<Cite>
Und das sieht nun so aus:
"
Der Inhalt des Zitates mit Hervorhebung '@em="P.H."' und Seitenangabe
'@page="5f"'
"
[Herv. v. P.H.](nudel:5f)
"
Der Inhalt des Zitates
"
(popo)
"
Der Inhalt des Zitates
"
(nudel)
Es gibt also zwei Versionen, wie mit dem Katalog gearbeitet werden kann.
Dafür gibt es den Hilfstag
CiteCatalogRef, welcher
den Ort und die Art der Ausgabe bestimmt.
- CiteCatalogRef style="strict|compact"
2.4.4.1. Fortlaufende Fußnoten - @style=''strict''
In der ersten Version wird wird pro Zitat eine Fußnote
als Verweis auf den Originaltext am Ende des
Dokumentes angehangen. Dies geschieht mit dem Einfügen des
CiteCatalogRef-Tags an der entsprechenden
Stelle. Dies sollte am Besten ein Pagefoot sein,
den wir hier nun auch verwenden. Da dies eine sehr strikte Variante
des Zitierens ist, wird das 'style'-Attribut von CiteCatalogRef
auch so gesetzt: '@style="strict"'.
Gleichzeitig werden in diese Nummerierung alle Fußnoten mit automatischer
Zählung einbezogen und dargestellt. Das sind die Fußnoten mit
Footnote/@class="auto".
First Name
'Der Titel des Werkes',
Band 2,
2.Aufl.,
Zumbelstadt,
1840, S.5f; [nudel]
First Name
'Der Titel des zweiten Werkes',
o.O.,
o.J.
; [popo]
First Name,
a.a.O
; [nudel]
2.4.4.2. Nur Quellenauflistung - @style=''compact''
Bei der zweiten Version wird einfach nur der Katalog in der
Standardform ausgegeben. Dafür wird '@style="compact"' gesetzt.
Da hier keine Verlinkung zwischen Zitat und dem Werk, aus
welchem zitiert wurde, stattfindet, sollte man die Attribute
'Cite/@page' und 'Cite/@src' bemühen, um die Seite (page) und die
Quelle (src) kenntlich zu machen. Diese Attribute werden in Version
1 nicht ausgewertet, d. h. visualisiert.
First Name
'Der Titel des Werkes',
Band 2,
2.Aufl.,
Zumbelstadt,
1840; [nudel]
First Name
'Der Titel des zweiten Werkes',
o.O.,
o.J.
; [popo]
2.5. Internes Zitat - cite
Nun will ich zitieren <cite>und das zitierte</cite> fügt sich
einfach ein. Das sieht dann so aus:
Nun will ich zitieren "und das zitierte" fügt sich
einfach ein.
Will man innerhalb "eines Textabschnittes zitieren", so benutzt man
den üblichen HTML-cite-Tag, der aber nun als XML interpretiert wird. Diese
inline Zitat macht keinen eigenen Absatz, sondern fügt sich in den
Textfluß ein und umfasst alles automatisch mit Quoten "...".
Man beachte, dass hier die Groß- und Kleinschreibung in XML beachtet wird.
Klein
geschriebenes 'cite' ist ein inline Zitat und ohne Attribute, ein
großes
'Cite' ist eines mit eigenem Absatz.
2.6. Absatz - P und PP
<P>
der Inhalt
</P>
P bezeichnet einen Absatz oder Paragraph.
Dabei geht der Absatz wegen möglicher Seitenbemerkungen nur auf 75% der
Seitenbreite. Will man über die gesamte Seite schreiben, dann muss man den
Tag
PP verwenden.
So sieht es dann aus:
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
Dies ist ein Absatz über die volle Breite.
2.7. Seitenbemerkung - CommentHead
Die Seiten- oder Randbemerkung sollte möglichst kurz und
prägnant sein,
da sie auch für die Strukturübersicht Verwendung findet. Man sollte
sie
nicht
als Konspekt benutzen, da dies wieder eine ganz andere Form ist.
<CommentHead title*="Inhalt der Bemerkung" >
der Inhalt
</CommentHead>
|
Dies ist ein Absatz, an dessen Seite eine Bemerkung platziert werden soll.
Dies ist ein Absatz, an dessen Seite eine Bemerkung platziert werden soll.
Dies ist ein Absatz, an dessen Seite eine Bemerkung platziert werden soll.
Dies ist ein Absatz, an dessen Seite eine Bemerkung platziert werden soll.
| [Inhalt der Bemerkung] |
2.8. Kommentar - Comment
<Comment>
der Inhalt des Kommentars
</Comment>
{
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
Dies ist ein Kommentar.
(d.V.)}
2.9. Fußnote - Footnote
2.9.1. Feste Nummerierung - vorgegebenes Dokument
Feste Nummerierung ist vorgesehen, wenn man z.B. Originale in XML-Form
überträgt
und die Nummerierung der Fußnoten beibehalten will. Dann ist man selbst
verantwortlich, wo die Fußnoten erscheinen werden. So macht man zuerst
einen
Link, auch Refernz gennannt, und dann die eigentliche Fußnote, wo man sie
hinhaben möchte. Eine Fußnote allgemein hat folgende Form:
<Footnote number="Nummer der Fußnote" class="Klasse der Fußnote"
>
der Inhalt
</Footnote>
Eine Fußnote ist keine Endnote, jedenfalls muss sie es nicht sein. D. h.,
dass
man
den Inhalt der Fußnote dorthin setzen kann, wo man ihn haben will, und
nicht nur
an das Ende des HTML-Files. Dazu benötigt man 2 Fußnoten Tags.
-
Referenzfußnote
ist ein Tag zum Festlegen der Verlinkungsstelle. Hier muss die 'class' nicht
angegeben werden, sie ist automatisch 'class="ref"', welches bedeutet, dass
dieser Fußnoten Tag nur die Referenz auf den eigentlichen Inhalt
darstellt.
Der Inhalt dieses Tags kann das letzte Wort des mit der Fußnote
versehenden
Textes sein.
-
Inhaltsfußnote Der Tag zum Darstellen des Inhaltes der
Fußnote
selbst. Dieser
Tag hat die 'class="noref"' und er umschließt den darzustellenden
Inhalt.
Die Nummer der Fußnote sollte fest gegeben werden, oder man
verlässt sich
auf eine interne Zählung. Beide Zählungen sollten sich nicht
überschneiden.
Intern gezählten wird ein Unterstrich nachgestellt.
Wird keine Klasse angegeben, dann ist die Fußnote automatisch ein
Verweis und das ist gleichbedeutend mit der Angabe @class="ref".
Soll hingegen der Inhalt der Fußnote beschrieben werden, so hat
der Tag die Angabe @class="noref".
Die Referenzfußnote selbst muss keinen Inhalt
haben, man kann sie all einen einzigen Tag in verkürzter Form darstellen.
Dies ist die Referenzfußnote mit fester Nummerierung
<Footnote number="255">
Das Ende dieses Texte wird mit der Fußnotenreferenz
versehen.
<Footnote>.
Und nun
eine mit automatischer Nummerierung .
Hier habe wir einen Text mit einem einfachen Fußnotentag als Referenz.
<Footnote class="ref" number="88" />
Das heißt, eine Referenzfußnote muss selbst nicht noch Text als Tag mit
öffnendem
und schließendem Tag einfasse.
Dies ist die 2. oder eigentliche Fußnote.
<Footnote number="255" class="noref">
Das ist nun der Inhalt oder
Text der Fußnote selbst.
<Footnote>
Aber natürlich kann man die Fußnoten auch gerne im Pagefoot Tag
sammeln am Ende
einer Seite.
2.9.2. Automatische Nummerierung - eigenes Dokument
Bei dieser Art der Fußnoten erspart man sich das Nummerieren und
umständliche
Auseinanderziehen der Fußnote in zwei separable Tags. Wir brauchen also
nur
einen Tag pro Fußnote, welcher durch die 'class="auto"' gekennzeichnet
ist.
<Footnote class="auto" >
der Inhalt
</Footnote>
Aber die Fußnoten werden gesammelt am Ende des Dokumentes,
bzw. wo CiteCatalogRef mit @style="strict",
in der vorkommenden Reihenfolge dargestellt und an dieser Stelle ihr Inhalt mit
der fortlaufenden Nummer indiziert.
Weiterer Vorteil ist, diese Nummerierung fügt sich in die der Zitate ein,
welche
auf den Zitatkatalog verweisen, falls es solche gibt. D. h. dort, wo der Tag
CiteCatalogRef im Seitenquelltext steht, das sollte das Ende des
Dokumentes sein, dort werden auch die automatischen Fußnoten dargestellt.
2.10. Seitenfuß - Pagefoot
<Pagefoot>
<Footnote number="Nummer der Fußnote" class="noref" >
der Inhalt
</Footnote>
</Pagefoot>
Insbesondere im Zusammenhang mit den Fußnoten existiert ein Tag, welcher
das
Ende
einer Seite bezüglich des normalen Fließtextes kennzeichnet. Wie
oftmals ist
dieser Abschnitt mit einer horizontalen Linie gekennzeichnet und hier sollte man
die Fußnoten mit ihren eigentlichen Inhalten platzieren.
Es ist auch sinnvoll diesen Abschnitt mit der Seitenangabe zu verbinden. Ein
Seitenfuß sieht
dann wie folgt aus:
Dies ist der eigentliche Inhalt der Fußnote 1 eines Zitates im
entsprechenden Abschnitt dieses Dokumentes.
Dies ist der eigentliche Inhalt der Fußnote 256.
2.11. Wichtiger Punkt - CardinalPoint
Dieser Tag sollte wirklich nur für ganz wichtige Sachen verwendet
werden
und auch nicht zuviel Inhalt bekommen. Im Wesentlichen stellt er eine rote
Umrahmung zur Verfügung und wird auch in die Strukturübersicht
übernommen.
Man kann in ihm Zitate und auch Paragraphen platzieren.
Hier sollten wirklich nur wichtige Sachen rein und zuviele rote Kästen sind
nicht schön.
2.12. Dokumentbeschreibung - Abstract
Der Abstract-Tag enthält die Informationen über die ihn
enthaltene
Datei.
Hier der entsprechende Ausschnitt aus der entsprechenden DTD.
<!ELEMENT Abstract (#PCDATA|p|Abstract)*>
<!ATTLIST Abstract
authorshort CDATA #IMPLIED
authorsfirst CDATA #IMPLIED
author CDATA #IMPLIED
coauthors CDATA #IMPLIED
email CDATA #IMPLIED
title CDATA #REQUIRED
subtitle CDATA #IMPLIED
description CDATA #IMPLIED
date CDATA #IMPLIED
type (original|excerpt) "original"
class (classified|innercircle|official|open) "open"
origin CDATA #IMPLIED
publisher CDATA #IMPLIED
isbn CDATA #IMPLIED
volume CDATA #IMPLIED
storage CDATA #IMPLIED
src CDATA #IMPLIED
state CDATA #IMPLIED
version CDATA #IMPLIED
keywords CDATA #IMPLIED
>
Hierbei entsprechen die einzelnen Attribute in der Attributeliste 'ATTRLIST' des
Tags Abstract
den möglichen Attributen in der XML-Datei. Die wichtigsten sind Autor
Nachname
'author',
Vorname 'authorsfirst', Titel 'title',
Kurzbeschreibung 'description', sowie Stichworte 'keywords'. In 'storage'
wird die Art der Speicherung eingetragen, z.B. "15KB, rtf, gz".
Der Status 'state' versteht sich von selbst, z.B. "in Arbeit".
Manche Attribute wie @title werden einfach nur angezeigt, aber
manche beeinflussen die Darstellung selbst.
2.12.1. Abstract/@type=''excerpt''
Manchmal gibt es geschachtelte Abstract.
Weshalb der 2. Abstract-Tag? Wenn man als Typ 'excerpt'
einträgt, so geht
der
Prozessor davon aus, dass es einen zweiten Abstract-Tag gibt. Im
ersten
Abstract stehen die Daten vom Exzerpt selbst, d. h. sein eigener
Titel usw.
Im inneren Abstract, dem 2. stehen dagegen die Daten des
Originalfiles, sein
Titel und Autor usw. Man hat in den seltensten Fällen das Original
selbst in unserer XML-Form, wo soll man sonst die Daten über das Original
herbekommen. Liegt das doch mal in unserer Form vor und hat somit einen
eigenen Abstract, dann wird der Prozessor mit einem Schalter
bei seinem Aufruf darauf aufmerksam gemacht und er holt sich die Daten dann
aus dem Originalfile selbst.
Die Originalfiledaten verwende ich übrigens auch für die Anzeige in
der Übersicht-HTML-Seite, der so genannten Indexseite.
<Abstract ...>
Daten für das Exzerpt
<Abstract ...>
Daten des Originals
</Abstract>
</Abstract>
2.12.2. Abstract/@type=''original''
Der andere Typ ist im Moment 'original', wobei nur ein Abstract
erwartet wird.
Wenn ihr kein 'type' Attribut im Abstract angebt, wird
automatisch davon
ausgegangen, dass ihr 'original' gewählt habt.
Diese File hat folgenden alleinigen
Abstract, da es ein Original
ist:
<Abstract
authorsfirst="Peter"
author="Heilbronn"
title="Beschreibung des internen XML-Formates"
description="Dieses Dokument beschreibt die grundlegenden Tags unseres
internen Exzerpt-Formates um eigene Dateien einbinden zu können."
date="07/2003"
/>
2.12.3. Langer Zusatz- oder Informationstext - Abstract/P|Cite
Eine Beschreibung ist grundsätzlich im
Abstract untergebracht.
Falls eine Beschreibung zu einem Dokument gegeben werden
soll, die länger ist und strukturiert ist, z.B. mit Listen, fügt man diese
als Fließtext mit eigenen Paragraphen ein.
<Abstract
title="Das Lalala"
author="Originalautorname"
authorsfirst="Originalautorvorname"
>
<P>
Hier kommt die Beschreibung hin.
</P>
<P>
Sie kann auch aus mehreren P und Cite-Tags bestehen.
</P>
</Abstract>.
Natrlich kann man beim Exzerpt dem inneren, also dem Original-Abstract-Tag,
und auch dem aeusseren
Abstract eine Beschreibung geben.
Die Kurzbeschreibung ist der eigentliche Abstract, wie er bei
Fachveröffentlichungen als Begriff verwendet wird. Sie wird im Dokument
selbst
als Section allem anderen vorangestellt und statisch als
Section/@title="Kurzbeschreibung" gekennzeichnet.
Diese Beschreibung ist übrigens dass, was in den Indexfiles, d. h. den
Übersichtsseiten, als Informationstext zum Link erscheint und in der
Sitemap mit einer Klappbox versehen angesehen werden kann.
2.12.4. Kurzer Zusatz- oder Informationstext - Abstract/@desctiption
Der Text in Abstract/@description ist als Kurzbeschreibung gedacht,
die ohne Schnörkel in den Indexseiten dargestellt wird.
Sie wird als Text in der Sitemap
einfach so dargestellt, _ohne_ Klappbox. D. h., wenn er eingetragen wird, dann
bitte sehr kurz.
2.13. Dokument
Ein Dokument meint, wenn nicht anders bezeichnet, eine XML-Datei. Diese wird in
eine oder mehrere HTML-Dateien mittels eines oder mehrerer XSL-Stylesheets
übersetzt. Jede entstandene HTML-Datei kann man als Sicht auf die
zugrunde liegende XML-Datei auffassen. Die XML-Datei wird auch als Quelldatei
(source) bezeichnet und eine aus ihr resultierende HTML-Datei als Zieldatei
(target). Es wird auch stillschweigend davon ausgegangen, dass diese XML-Datei
unsere DTD benutzt, d. h. die oben erklärten Tags in ihrem Zusammenhang.
Werden aus einer XML-Datei mehrere Zieldateien, auch HTML-Repräsentanten
genannt, erzeugt, so ist es oft so, dass bestimmte Tags nur für die eine
Sicht
oder einen Repräsentanten ausgewertet werden und andere nur für den
anderen.
Zumeist bleibt aber z.B. die Kapitelstruktur unberührt, d. h., die
Section
oder
Subsection-Tags werden in fast jeder Sicht benutzt und ausgewertet.
Werden bestimmte Tags fast ausschließlich von einer bestimmten Sicht
benutzt, so
formen sie quasi ein extra Dokument innerhalb des Dokumentes. Dies nennt man
auch inneres Dokument. Davon kann es beliebig (endlich) viele geben. Ein solches
ist z.B. der Konspekt oder die Struktur.
Streng genommen ist die am meisten verwendete Form der Darstellung, das
Exzerpt, auch eine Sicht, wenn auch die
Hauptsicht.
2.13.1. Sichten - Struktur
Die einzigen bisher
erstellten Sichten sind also Exzerpt, Konspekt und
Struktur. Eine Sicht
bedeutet technisch, dass die gleiche Datei mit einem anderen Stylesheet
übersetzt wird und dabei eine andere Datei, eine andere Sicht auf die selbe
Quelldatei erzeugt.
Üersetzt man ein
Exzerpt-XML-File, also eines, welches mit der notice.dtd konform
geht, mit dem excerpt.structure.xsl Stylesheet. Dann werden nur die
für die Struktur wichtigen Tags wie z.B. 'CommentHead' dargestellt. Es
entsteht
ein Strukturfile als HTML-Repräsentant.
Übersetzt man
das gleiche File mit dem Konspekt-Stylesheet conspectus.xsl, so
wird eine neue Datei erzeugt, in welcher nur die Bestandteile angezeigt werden,
welche im Konspekt-Tag stehen.
2.13.2. Conspectus - Konspekt als ''innere'' oder eigene Datei
<Conspectus style="exclusive|inclusive">
</Conspectus>
Ein Konspekt ist eine inhaltliche Zusammenfassung eines Textes gegenüber
einem
Exzerpt, welches quasi eine zitatorientierte Zusammenfassung ist und auch meist
viel umfänglicher als ein Konspekt daherkommt. Man sollte sich also kurz
fassen.
Ein Konspekt kann eine andere Datei als das Exzerpt sein, muss es aber nicht.
Das Wichtige ist, dass man alles, was im Konspekt erscheinen soll, im
Konspekt-Tag einschließt.
Dieser Tag sollte innerhalb von Abschnitten oder Unterabschnitten stehen,
diese nicht umfassen. Ansonsten kann man innerhalb des <Conspectus>
Tags alle anderen Tags außer Section,
Subsection und Fußnoten
verwenden.
Also kann man den Konspekt auch aus dem Exzerpt-file generieren. Dabei wird die
gleiche Kapitel- oder Abschnittseinteilung genommen wie beim Exzerpt und
es gibt automatisch eine Verlinkung zwischen den Überschriften mit den
kleinen
'>>E' oder '>>K' gekennzeichnet. Alles, was in der Exzerptdatei innerhalb von
Konspekt-Tags steht, wird in den Konspekt übernommen und erscheint
im Allgemeinen nicht
im umgesetzten Exzerpthypertextfile. Also werden zwei separate HTML-Dateien
erstellt, eines für das Exzerpt und eines für den Konspekt.
Das 'style' Attribute sagt nun, ob der Inhalt des Konspekt-Tags ausschließlich
'style="exclusive"' nur im Konspektfile dargestellt werden soll, oder, ob er
ebenso im Exzerptfile zu sehen sein soll. Dies betrifft natürlich z.B. auch
ein
zugehöriges Strukturfile. Das 'style' Attribut macht natürlich nur
Sinn, wenn
der Konspekt als innere Datei, also als Tag-Folge innerhalb des
Exzerptfiles definiert wird.
Hier nun ein live Beispiel von einem Exzerpt, welches als innere Dokumente einen
Konspekt und eine Struktur definiert hat. Dazu gibt es noch mehrere
Originalfiles, welche in HTML-Form vorliegen und also nur kopiert werden. Der
folgende Abschnitt befindet sich im entsprechenden Indexfile, welches
auf unser Dokument als Übersichtsseite verweist (dazu später mehr).
<
IndexItem
src="mxks/excerpt/peter2Postone.ZeitArbeitUndGesellHerr.xml"
dest="files/other/peter2Postone.ZeitArbeitUndGesellHerr.html"
base="../.."
stylesheet="excerpt/excerpt.xsl"
origsrc="mxks/excerpt/orig/Postone.vorwort.htm"
origdest="files/other/Postone.vorwort.htm"
style="actual"
>
<DocInfo name="structure"
src="mxks/excerpt/peter2Postone.ZeitArbeitUndGesellHerr.xml"
dest="files/other/peter2Postone.ZeitArbeitUndGesellHerr.structure.html"
base="../.."
stylesheet="structure/excerpt.structure.xsl"
buildmode="build"
/>
<DocInfo name="conspectus"
src="mxks/excerpt/peter2Postone.ZeitArbeitUndGesellHerr.xml"
dest="files/other/peter2Postone.ZeitArbeitUndGesellHerr.conspectus.html"
base="../.."
stylesheet="conspectus/excerpt.conspectus.xsl"
buildmode="build"
/>
<DocInfo name="original"
src="mxks/excerpt/orig/Postone.kap8.htm"
dest="files/other/Postone.kap8.htm"
base="../.."
buildmode="copy"
/>
<DocInfo name="original1"
src="mxks/excerpt/orig/Postone.prol.htm"
dest="files/other/Postone.prol.htm"
base="../.."
buildmode="copy"
/>
</
IndexItem>
2.13.3. Originale und innere Verlinkung
Einem Exzerpt kann über den IndexItem-Tag auch ein
Originalfile
zugeordnet werden. Ein Original ist immer eine eigene Datei, nicht wie der
Konspekt.
Ist dies ein Fremdformat, so wird es nur kopiert
(IndexItem/@origbuildmode="nobuild"). Ist es hingegen in unserem
XML-Format, so kann es mit IndexItem/@origbuildmode="build"
übersetzt werden. Mit dem Schalter
IndexItem/@origlinkmode="on" wird es automatisch
mit Exzerpt oder Konspekt über die Überschriften intern verlinkt.
Ansonsten erreicht man dieses File nur über den Link im Dokumentenkopf des
Exzerpts oder Konspekts.
2.13.4. Baumstruktur eines Dokuments
Alle XML-Dokumente haben einen Wurzel-Tag, das heißt, dass dieses der
äußerste Tag
ist, der
alle anderen enthält. Er sagt an, welcher Art das Dokument
ist.
Richtigerweise passiert dies technisch gesehen in der 'DOCTYPE'-Anweisung, sei
hier aber nicht weiter beachtet. Hier nun die echte
DocTypeDefinition
(DTD),die
XML-Formatbeschreibung.
Im wesentlichen gibt es im Moment nur die Typen 'Excerpt' und 'Notice'. Dieses
Dokument ist eine Notiz. Der Typ eines Dokumentes bestimmt, wie der Inhalt
dargestellt wird, z.B. den Kopf. Die eigentliche Darstellung von der technischen
Seite her wird mit XSL-Stylesheets generiert, worauf ich aber hier auch nicht
weiter eingehen will.
Der am meisten verwendete Dokumenttyp ist das Exzerpt. So ist in unserem
Beispiel dies auch der Wurzel-Tag.
<Excerpt >
<Section title*="Titel des Kapitels" index="feste Nummerierung" >
</Section>
<Section title*="Titel des Kapitels" index="feste Nummerierung" >
der Inhalt
</Section>
</Excerpt>
2.14. Kapitel und Unterkapitel - Section, Subsection
<Section title*="Titel des Kapitels" index="feste Nummerierung" >
der Inhalt
</Section>
Dies ist ein Kapitel. Es kann Unterkapitel aber keine Kapitel enthalten. Es wird
einmal im Inhaltsverzeichnis dargestellt (siehe diese Seite ganz oben) und dann
noch einmal in der Reihenfolge mit seinem Inhalt. Das Kapitel 'Die Tags' ist ein
Beispiel.
<Subsection title*="Titel des Unterkapitels" index="feste Nummerierung"
>
der Inhalt
</Subsection>
Dies ist ein Unterkapitel. Es kann weitere Unterkapitel aber keine Kapitel
enthalten. Unterkapitel müssen sich in einem Kapitel befinden, können
aber auch
verschachtelt werden.
Es wird einmal im Inhaltsverzeichnis dargestellt (siehe diese Seite ganz oben)
und
dann noch einmal in der Reihenfolge mit seinem Inhalt. Das Unterkapitel 'Kapitel
und Unterkapitel' ist selbst ein Beispiel. Zur Verschachtelung als Beispiel
folgendes Unterunterkapitel 'Nummerierung'.
a.) Nummerierung
Normalerweise geschieht die Nummerierung automatisch mit arabischen Zahlen. Will
man aber eine besondere angeben, dann benutzt man bei 'Section' und 'Subsection'
das 'index'-Attribut, z.B. @index="a.)". Es gibt auch die
Möglichk einen Anfangswert
zu setzen, mit dem 'count'-Attribut.
Hier der notwendige "Trick":
<Subsection title="III" index=""> so ist _kein_ Titel und nur die
Nummerierung definiert. Da nur @title ein Link wird und
@index="" die automatische Nummerierung verhindert.
<Subsection title="Herder" index="III">, falls ein Titel gegeben ist und
eine feste Numerierung, also ganz normal angeben.
2.15. Seitenangabe - Page
Dieser Tag mit Namen 'Page' ist eine Seitenangabe und kann auch z.B. in Zitaten
verwendet werden, wenn
man wissen will, wo der Seitenumbruch im Zitat ist. Das einzige Attribut ist
'number'
und gibt die Seitennummer an. Implizit wird ein HTML-Anker (anchor) angelegt und
dieser hat die Referenz 'pageXXX',
wobei XXX die Seitennummer repräsentiert. In unserem Fall ist dies
'page55'. Es wird sowohl
das Attribut für XHTML a.id="pageXXX" also auch für HTML
a.name="pageXXX" im HTML-Code gesetzt.
<Page number="55" />
Und so sieht das Ganze dann aus:
-55-
2.16. HTML-Tags
Innerhalb z.B. eines Paragraphs kann man alle gängigen html-Tags
verwenden,
z.B. 'table', 'br', 'ol', 'b', 'a' ... Man sollte sich aber auf die wichtigsten
beschränken, damit eine Konvertierung nicht allzu schwierig wird. Man kann
auch
css-Styles verwenden, welche dann aber eben auch bei der Übertragung
halt
schwieriger werden. Man sollte z.B. auf absolute Positionierung verzichten.
Ebenso
ist es nicht ratsam Hypertext-Links zu benutzen, sofern sie keine absoluten
Pfade verwenden, oder man genau weiß wo das Target-Dokument zu finden ist.
2.17. Bild - img
Will man ein Bild in ein XML-File unserer Art einfügen, so kann man einfach
den normalen HTML-Tag img benutzen.
<img src="wo ist es" alt="bildkuerzel" />
Für img/@src sollte man einen Ordner vorsehen, der den
gleichen Namen besitzt,
wie das XML-File selbst. Dort sollten alle Bilder oder sonstige zusätzlich
verlinkte Dateien hineinkommen. Dann kann ich ganz einfach mit einer
Ordnerkopie die Daten in das Webserververzeichnis kopieren.
Das Attribut img/@alt beinhaltet die Zeichenkette, die angezeigt
wird, falls
jemand seinen Browser so eingestellt hat, dass Bilder nicht angezeigt werden.
Es ist zwar ein optionales Attribut, sollte aber wegen guten Stiles angegeben
werden und ist auch vom W3C als notwendig angesehen.
2.18. Entities
Eine Entity ist ein Platzhalter. Mit ihr kann man quasi eine Textersetzung
durchführen. Sie wird auch benutzt, um Zeichen darzustellen, die sonst von
XML
als Strukturmerkmal interpretiert wrden. Will man ein
pures Größer-Zeichen einfügen,
so ergibt dies einen Fehler, da XML hier glaubt, man will einen Tag öffnen.
Dafür benutzt man dann die Schreibweise > und 'gt' steht
für
greater.
Jede Entity ist so aufgebaut: &CODE;. Die verschiedenen Codes und
Abkürzungen lassen sich z.B. bei
Selfhtml
nachschlagen. So ist das
Zeichen &, was den Beginn einer Entity definiert, selbst darstellbar als
Entity in der Form: & mit 'amp' für ampersand.
2.19. Links - Ref
<Ref link*="relativer Zielpfad" anchor="dokumentinterner Anker" title="Name"
>
der Inhalt, falls kein Name gegeben ist
</Subsection>
Der 'Ref'-Link arbeitet im Gegensatz zum reinen HTML-Link mit unserer umgebenden
Struktur zusammen. Der letztendliche
absolute Pfad wird über das dem Dokument entsprechenden 'IndexItem' im
zugehörigen Index-File bestimmt. Dieses 'IndexItem' enthält eine
'base'-Attribut, welches den relativen Zielpfad zu einem absoluten ergänzt.
Damit soll ein bisschen Hilfe für den Linksalat gegeben werden.
Hat man einen externen oder sonstwie absoluten Link, dann sollte man im
Augenblick den normalen HTML-Link verwenden.
Todo:
Es ist geplant, dies noch weiter zu vereinfachen, indem für bestimmte
Dokumente
eindeutige Namen vergeben werden, mit deren Hilfe selbst die relative Pfadangabe
automatisch herausgefunden werden kann. Dies ist aber noch zu tun.
Der Inhalt der internen Nummerierung
Der Inhalt der festen
Nummerierung.
3. Ansehen von XML ohne Compiler
Da nun einige mit dem XML-Format arbeiten möchten, ergibt sich die
Schwierigkeit, sich sein File vernünftigen anzusehen. Dies sollte für
moderne
Browser zu lösen sein.
Anbei ist ein
XML-Paket file mit den
nötigen
Zutaten. Es enthält die
entsprechenden Stylesheets (XSL) und Dokumentbeschreibungen (DTD), sowie ein
Test XML-File mit Namen
xml.format.xml.
Also:
3.1. Entpacken und Test
1. Entpacken des gepackten Paketes in einen am besten neuen Ordner.
2. Öffnen des Files xml.format.xml im Browser.
Nun sollte man das File in unserer bekannten Form sehen können. Bei mir
mit dem
Mozilla 0.9.8 (Mozilla/5.0 (X11; U; Linux i686; en-US; rv:0.9.8)
Gecko/20020204) funktioniert das.
Wenn man das Servicepack(!) für XML von Micors*ft installiert, dann kann
man
sich
im IE 5 die Files am besten von den mir probierten Browsern darstellen. Vorher
ist da nichts zu machen, aber auch gar nichts.
{
Bei der rasanten technischen Entwicklung ist eben gesagtes sicherlich schon
lange überflüssig.
(d.V.)}
3.2. Eigene Datei vorbereiten
Wie man nun ein eigenes File so ansehen kann, kann man sich am Beispiel
unseres xml.format.xml ansehen. Öffnet man es in einem
Editor(!), dann kann
man sich den Quelltext ansehen. Öffnet man das File im Browser und
lässt
sich den Quelltext anzeigen, so sieht man meistens auch den XML-Quelltext.
1. das eigene File in den Ordner mit den DTD- und XSL-Dateien kopieren
2. folgende 3 Zeilen sollten als erste(!) Zeilen im File eingetragen werden.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- DOCTYPE Excerpt SYSTEM "notice.dtd" -->
<?xml-stylesheet type="text/xsl" href="excerpt/excerpt.browser.xsl"?>
3. speichern und sich das File im Browser ansehen.
3.3. Erklärung
Ok, nun noch eine kurze Erklärung:
1. Zeile ist ein Muss als erste Zeile in jedem XML-File, sie beschreibt, dass
dieses File ein XML-File (?xml) ist, von welcher version (1.0) und mit
welchem Zeichensatz (ISO-8859-1, mit deutschen Umlauten).
2. Zeile beschreibt den Dokumententyp. Hier wird der Name das Wurzelknotens,
das ist der erste und äußerste Tag (z.B. Exzerpt) bekannt gemacht und
gesagt, wo
sich die Dokumentbeschreibung findet (SYSTEM "notice.dtd"). Im Augenblick
macht das Validieren gegen unsere DTD noch solche Probleme, dass die
Zeile erst einmal nicht benutzt wird.
3. Zeile nun sagt, welchen Stylesheet man automatisch benutzen will
(?xml-stylesheet) und wo sich der Stylesheet in Textform findet
(excerpt.browser.xsl). Diese Zeile benutzt der Browser um nun seine
Konvertierungsmaschine von XML nach HTML anzuwerfen, sie mit dem Stylesheet
zu füttern und dann das File darzustellen.
Allgemein kann diese Vorschrift als Schablone dienen. Einfach die entsprechende
DTD und den Stylesheet
eintragen, wenn man anders geartete Dokumente angezeigt haben möchte.
Wenn ihr Schwierigkeiten mit den Browsern habt, dann müssen wir uns im
einzelnen darum kümmern und den Stylesheet anpassen. Der Browser führt
zum
Teil nicht alle Anweisungen richtig aus. So werden Nummerierungen verändert
oder manche andere Kleinigkeit. Daran kann ich allerdings wenig ändern.
Jedenfalls hat das KEINE Auswirkungen darauf, wie es auf der Webseite
dargestellt wird. Da benutze ich direkt einen speziellen XSL-Interpreter.
Viel Spaß
4. Die interne Struktur
4.1. Übersicht und Technisches
Alle Informationen, sowohl die reinen Inhalte, als auch die für die
Übersetzung
notwendigen sind fast ausschließlich in XML-Dateien angelegt. Ausnahmen sind
z.B.
Originaldateien (pdf,...) und Bilder.
Zur Erstellung der Seiten wird das Werkzeug
ANT verwendet und dessen
XML-Prozessor nach der Definition 'trax' benutzt. Die für die automatische
Prozessierung notwendigen Build-Dateien werden speziell für dieses Tool
erzeugt.
Ausgangspunkt der Übersetzung ist ein von Hand erstelltes
Grund-Ant-Build-File
'build.xml'.
Der Rest an Build-Files wird automatisch erzeugt.
Viele Informationen über die Struktur erschließen sich durch das
Lesen der
entsprechenden DTD-Dateien, z.B. der
Indexbeschreibung.
Die Übersetzung wird von der Kommandozeile angestossen. Bis jetzt wurde
noch kein
entsprechendes grafisches Werkzeug entwickelt.
4.2. Das XML-Projekt
Der 'xml' Unterordner im Projekt enthält folgende Ordner und Dateien:
-
xml = src.home
-
dtd, alle Document Type Definitions
-
xsl, alle XSL-Stylesheets und dazugehörige Dateien
-
mxks, die XML-Hauptseiten, z.B. alle Exzerpte und Indexseiten
und
auch das Strukturfile
-
misc, weiter XML-Seiten, wie Termine und Links
-
script, enthält verschiedene 'shell' und 'sed'
Skripte
-
tmp
- ...
- build.xml, ist das HauptBuild-File des Projektes.
- Readme.xml
Dieser Ordner ist der Quellordner und Bezugspunkt für alle Pfade im
Quellbereich. In diesem Order als 'working directory' wird auch 'ant'
auf der Kommandozeile aufgerufen.
4.3. ANT-Buildfiles
4.3.1. Environement - Umgebungsvariable
4.3.2. Pfade
4.3.3. xmlcatalog
4.4. Strukturfile oder Navigationsfile - mxks/main.navbar.xml
- Nav base=".." site="www.mxks.de"
- Abstract
- NavParam
- ...
- BuildArgs
- NavGroup name="firstlevel", title="Hauptseite" label="MXKS"
base=".."
- NavGroup
- ...
- NavItem title="YYY" buildmode="index|normal|..."
- ...
- NavGroup name="XXX"
Die interne Struktur des Projektes kennt
ein Hauptfile. Dieses heißt
'main.navbar.xml' und ist das
Navigationsfile. Hier wird die baumartige
Struktur
der gesamten Website
angelegt. Das Wurzelelement ist
Nav und die einzelnen
Ebenen sind
die
NavGroups. Die Navigationsleisten jeder Seite, welche sie
führt, wird nur aus diesem einen Hauptfile heraus gebaut.
Die Navigationsbeschreibung enthält außer den Items und
Gruppen,
welche die Seiten und Ebenen repräsentieren, noch andere
Informationen. Das sind einerseits die NavParam, welche allgemeine
benamte Werte darstellen, also Key-Value-Paare. Das zweite Allgemeine an
Information sind die BuildArgs. Dieses ist ein Container, in
welchem sich 'ant' spezifische Daten befinden, wie property,
path und andere.
4.4.1. NavGroup - Ebene
Eine Navigationsgruppe entspricht einer Horizontalen, einer Ebene von
gleichrangigen Items, also Dokumenten, die von hier aus direkt zu erreichen
sind. Diese Dokumente sind also in dieser Ebene gruppiert.
Es bekommt jede Ebene eine sie
repräsentierende Hauptseite 'backlink' und einen Namen 'name' zugeordnet. Die
NavGroup einer eine Ebene repräsentierenden Seite enthält
ihrerseits
wieder NavItems. Sie enthält ebenso Farbangaben für
'active'
und
'inactive', in welcher ihr Label in den Navigationsleisten darzustellen ist.
NavGroups kann man natürlich ineinander schachteln, woraus
sich
eine im Navigationsfile beschriebene Baumstruktur der ganzen Website ergibt.
Es gibt genau eine oberste Gruppe, welche alle anderen und alle Items
enthalten muss. Diese trägt den Namen 'firstlevel'.
Da der @name zur Identifikation dient und z.B. keine Umlaute
enthalten darf, gibt es ein weiteres Attribut @label. Dieses Label
wird in der grafischen Darstellung benutzt, wenn es existiert. Sonst wird der
Name angezeigt.
4.4.2. NavItem - Einzelseite
Ein Navigationsitem ist im Wesentlichen eine Webseite, die mit anderen in einer
Navigationsgruppe zusammengefasst ist und über diese Gruppe verlinkt wird. Ein
solches Item kann selbst wieder eine Gruppe enthalten und somit Zugang zu einer
neuen Ebene/Gruppe sein.
Ein NavItem enthält einen Namen 'title' eine Quelldatei 'src'
einen
Stylesheet 'stylesheet', eine Zieldatei 'link', in welches sie mit dem
Stylesheet
umgewandelt wird und letztens eine dazu passende Pfadangabe zur Wurzeldatei der
gesamten Site namens 'base'.
Es existieren 3 Arten von durch XML-files repräsentierte Seitentypen.
Es gibt Seiten,
- die nur für sich stehen, Einzelseiten, wie z.B. die
'Termine'. Von den Einzelseiten gibt es solche, die nur Daten enthalten und
solche,
-
welche
Index-Files
genannt werden. Diese enthalten eine komplexe Struktur von Unterseiten.
- Die dritte Art sind die Seiten, die
eine ganze Ebene repräsentieren, wie z.B. 'Texte'.
Sie sind die Eröffnungsseiten einer neuen
NavGroup.
Wie bei den IndexItem kann man entsprechende
DocInfo-Tags verschachteln. Das ermöglicht, für die Indexseiten
noch z.B. Bilder oder andere abhängige Daten mit
DocInfo/@mode='dircopy' zu kopieren.
4.4.3. NavGroup - Automatismus
Eine Navigationsgruppe umfasst also eine Ebene, der ein XML-File als Hauptseite
zugeordnet ist. Das Übersetzen der grundsätzlichen Ebenen muss im
Moment noch per Hand in
einem Build-File beschrieben werden. Das sind z.B. alle Elemente aus der ersten
Ebene. Alle weiteren unteren Ebenen werden automatisch übersetzt, sobald
die entsprechende obere Ebene übersetzt wird.
So ruft z.B. ant main.build zum Übersetzen der obersten Ebene
auf.
'main.build' ist dabei der Name eines target im Haupt-Build-File
'build.xml' des Tools 'ant'. Von diesem target aus
wird mittels 'navbar2build.xsl' ein temporäres Build-File erstellt und
aufgerufen. Diese enthält die Informationen zum rekursiven Erstellen der
gesamten Unterseiten.
Der Aufruf erfolgt mit dem Namen der entsprechenden
NavGroup/@name, in unserem Falle 'firstlevel',
um die zu übersetzende Ebene zu kennzeichnen.
Aus den untergeordneten NavGroups bzw. NavItems wird
dann das Build-File zum Erstellen eben dieser gebaut.
4.5. Indexfiles - Automatismus
Bei der Übersetzung eines Indexfiles wird eine ganze Sequenz von
Übersetzungen
getätig.
- Erzeugen eines neuen Indexfiles inklusive aller externen Informationen, wie
z.B.
IndexGroupRef oder Exzerptfileinformationen
Abstract (exzerpt.index2index.xsl),
- daraus wird die repräsentierende HTML-Seite des Indexfiles erzeugt
(exzerpt.index.xsl)
und ebenso
- das Build-File zum Erstellen aller untergeordneten Seiten
(exzerpt.index2build.xsl).
- Schließlich wird die Übersetzung dieses neuen Build-Files
angestossen.
Die Baumstruktur eines Indexfiles wäre ungefähr wie folgt:
- Index
- Abstract
- IndexGroup
- IndexGroupRef
- IndexItem
- ...
- IndexGroup
- IndexItem
- IndexItemRef
- ...
Das Ganze nun etwas genauer.
Eine der großen Stärken des Projektes sind die Indexfiles. Sie
sind sowohl als
grafische Repräsentation, als auch als Prozessfiles zu sehen. Als Sichtfile
werden sie in eine
oder mehrere HTML-Seite umgesetzt, welche Links auf ihre IndexItems
und Informationen über diese enthält, welche aus diesen Files
selbst extrahiert wird (genauer aus dem Abstract).
Dabei kann man beliebig viele Sichten auf die indizierten Dateien kreieren, wie
z.B. Normalansicht und nach Autoren geordnet.
Die prozessuale Verwendung hingegen ist der Kern des Automatismus. Indexfiles
sind
durch NavItem/buildmode="index" gekennzeichnet. Dies lässt
einen ganz anderen Mechanismus aus, als zum Build einer normalen Seite.
Aus dem Indexfile wird ein weiteres Indexfile erstellt, in welchem alle
Informationen, die man aus den IndexItems extrahieren muss, wie
Autor IndexItem->Excerpt/Abstract/@author und Titel
IndexItem->Excerpt/Abstract/@title,
zusammengefasst sind, um z.B. Sortierungen vornehmen zu können.
(-> gibt an, dass die Informationen aus der entsprechenden Quelldatei geholt
werden mssen.)
Aus dieser neuen
Datei wird sodann ein neues Build-File erstellt, mit welchem
alle IndexItems übersetzt werden können und schließlich
wird dieses
File mit ANT aufgerufen und dadurch ein rekursives Erstellen der ganzen
zugehörigen Seiten automatisch ermöglicht.
Es werden zusätzlich Entscheidungen (ANT-Conditions) erzeugt, damit Seiten
nur neu übersetzt
werden, wenn sich damit zusammenhängende Dateien verändert haben, um
den Aufwand
zu senken. Dies ist noch nicht vollständig strukturiert, so dass man
manchmal
mit z.B. 'touch' unter Unix erzwingen muss, dass das Indexfile neu gebildet
werden, um die darunter liegenden Dateien neu zu kreieren.
4.5.1. IndexGroup
Eine Indexguppe fast mehrere Indexitems zu
einer
4.5.2. IndexItem - Exzerpte
- Exzerpt
- Konspekt
- Struktur
- Originalfile
- ...
- Bilder und sonstiges
Die IndexItems stellen den informativen Kernbestand dar. Sie
enthalten eine Fülle von Informationen. Wohl die wichtigsten sind die Quelldatei
'src', der Ort 'dest' oder die Datei, an welchem sie kopiert oder in welche sie
mit Hilfe des 'stylesheet' übersetzt werden soll. Der 'buildmode="build"'
gibt
z.B. an, ob eine Datei übersetzt werden soll. Meist sind die Files
Exzerpte.
|
Wenn wir ein Exzerpt vorliegen haben, dann gibt es die Möglichkeit,
Informationen über eine eventuelle Originaldatei abzulegen. Die
entsprechenden
Attribute sind analog 'origsrc','origdest', 'origbuildmode',... Damit ist es
möglich, dass im Exzerpt Links zur Originaldatei erstellt werden.
(Wie die Exzerptfiles selbst aufgebaut sind, ist in den ersten Abschnitten
dieses Dokuments beschrieben.)
Originaldateien können selbst wieder XML-Dateien oder statische Dokumente sein,
wie ein PDF. Wird 'origbuildmode="nobuild"' angegeben, bzw. dies ist die
Voreinstellung
beim Weglassen dieses Attributes in der DTD, dann wird das Originalfile nur
kopiert.
Wenn man den Build einschaltet 'origbuildmode="build"', dann wird mit dem
'origstylesheet'-Attribut festgelegt, mit welchem Stylesheet die Originaldatei
übersetzt werden soll.
| [Zusätzliche Originaldatei] |
|
Im Falle, dass wir nur ein statisches Originalfile haben, also auch kein
Exzerptfile, dann muss man als 'dest' den gleichen Wert eingeben wie für
'origdest' und sodann wird in der Index-HTML-Repräsentation auf dieses File
gelinkt. (Dies ist z.B. beim Medienprojekt der Falle, wo keine Exzerpte, sondern
gepackte Powerpoint Dateien als IndexItems verlinkt werden.)
| [Nur eine statische Originaldatei] |
|
Wenn dies nun der Fall ist, also ein Nicht-XML-File durch
das IndexItem repräsentiert wird, dann muss man einen
Abstract als ersten Tag in den IndexItem Tag einfügen,
damit auf der Index HTML-Seite zumindest Autor und Titel dieses Files zur
Verfügung stehen. Das absolute Minimum ist ein Abstract mit
nur dem Titel.
| [IndexItem/Abstract notwendig] |
Ist das Originalfile selbst ein XML-File unseres von unserem Doctype, dann kann
man nicht nur mit 'origbuildmode="build"' das automatische übersetzen
dieses Files
anstoßen, sondern mit 'origlinkmode="on"' veranlassen, dass die
entsprechenden Kapitel und Unterkapitel zwischen Exzerpt und Originaldatei
verlinkt werden können. (Dazu müssen sie natürlich übereinstimmen.)
4.5.3. DocInfo - Konspekt, Struktur, Bilder, ...
- IndexItem style="actual|main|normal"
- Abstract
- DocInfo buildmode="build|nobuild|copy|dircopy|dirpack"
name="conspect|structure|label|thumb|package"
- ...
- IndexItem
- ...
Ein IndexItem kann endlich viele DocInfo-Tags
enthalten. Diese Struktur ermöglicht verschiedenste Zusatzsichten und
Dateien zu
einem Exzerpt zu erstellen. Die wesentlichen Attribute sind 'name' und
'buildmode'.
An Hand des Attributes DocInfo/@name wird entschieden, wie der
DocInfo-Tag
in der Verlinkung zu interpretieren ist, um welche Art von Informationen es sich
im Dokument, bzw. inneren Dokukment, handelt.
| Attributwert | Interpretation |
| conspect | Die beschriebene Datei wird als Konspekt
interprätiert, ist meist ein inneres Dokument, es wird prozessiert
und bei der Verlinkung mit dem Exzerpt berücksichtigt. |
| structure | Es handelt sich um ein Strukturfile, es gilt
das Gleiche, wie für den Konspekt. |
| criticism | Dieses File wird als Kritik zum
Hauptdokument verlinkt (und erstellt). |
| label | Dies kennzeichnet ein Bild, welches dem Verweis
auf das Hauptfile auf der Indexseite vorangestellt wird. |
| thumb | Existiert nur mit einem Label und wird anstatt
diesem angezeigt, wenn das Label selbst zu umfangreich ist.
Beim Klicken auf das 'thumb'-Bildchen, wird das meist einfach nur größere
Label im Browser angezeigt, z.B. ein Übersichtsdiagramm.
|
| package | Dieses File beinhaltet Zusatzinformationen und
wird z.B. im Exzerptfile als 'Info' im Kopfbereicht verlinkt. |
| sonstiges | Wird nicht interpretiert, entscheidet sich
also nur an Hand des 'buildmode'. |
Das Attribut DocInfo/@buildmode wird vom XSL-Prozessor
bezüglich der
Übersetzung ausgewertet. Dabei kann z.B. eine Übersetzung mit einem
Stylesheet
erfolgen oder aber ein einfaches Kopieren, etc.
| Attributwert | Interpretation |
| build | Das durch 'src' gekennzeichnete File wird
mittels 'stylesheet' nach 'dest' übersetzt, z.B. Exzerpte. |
| copy | Das File wird einfach kopiert und umbenannt.
Dies wird meist bei Originalfiles oder Präsentationen der
Fall sein. |
| dircopy | In diesem Fall ist 'src' ein Ordner und der
gesamte Ordnerinhalt wird an die entsprechende Stelle 'dest' kopiert.
Das wird oft für das Kopieren von Ordnern mit benötigten
Bildern benutzt. |
| dirpack | Der Ordnerinhalt von 'src' wird als zip-file
nach 'dest' gepackt. Meist findet dies bei Zusatzinformationen
Anwendung. |
| nobuild | Hat weiter keine Bedeutung, außer , dass dieses
File nicht prozessiert wird. |
Das Wichtigste also ist, dass ein DocInfo einen Namen 'name' und
einen 'stylesheet' enthält. An Hand des Stylesheets wird das Quellfile
'src' in
das Zielfile 'dest' übersetzt, sofern 'buildmode="build"' eingestellt ist.
Ist
der Name z.B. 'conspect', dann wird dieses File als Konspekt zum
übergeordneten
Exzerptfile behandelt und entsprechend verlinkt und angezeigt.
Ein weiterer bekannter Name ist 'structure', mit welchem ein so gennantes
Strukturfile angelegt und mit dem Exzerpt verlinkt wird. In diesem werden z.B.
die
CommentHeads und andere Tags die die Struktur beschreiben
angezeigt.
Zwei weitere DocInfos gehören zusammen und betreffen Bilder. Wenn
'@name="label"' gesetzt ist, so wird das entsprechende File als Bilddatei vor
dem
Schriftzug verlinkt und in verkleinerter Form auf der Indexseite selbst
angezeigt. Ist die Bilddatei zu groß, so benutzt man für die Indexseite
eine
verkleinerte separate Bilddatei, welche dann angezeigt wird. Der entsprechende
Name ist dann 'thumb'. Beide Tag-Formen sollten den 'buildmode="copy"' besitzen,
da sonst die entsprechenden Bilddateien nicht in den Zieldateibaum kopiert
werden.
Die 'thumb' und 'label' DocInfo Tags können nicht nur
innerhalb von
IndexItem, sondern auch direkt innerhalb von
IndexGroup auftreten und somit nette Bildchen erzeugen.
Mit dem 'buildmode="dircopy"' veranlasst man den Prozessor dazu, den Ordner
'src' nach 'dest' zu kopieren, um z.B. eine Vielzahl von zu einem File gehörige
Bilddateien zu kopieren.
4.5.4. IndexItem/@style
Mit dem 'style'-Attribut lassen sich verschiedene Darstellungen
des entsprechenden IndexItems auf der Indexseite realisieren.
Normale Items haben das Attribut IndexItem/@style nicht gesetzt,
bzw. haben den Default-Wert "normal" aus der DTD.
D. h., wir haben einen dünnen grauen Rahmen um das Item gezeichnet.
Man kann dieses Attribut aber auch auf folgende Werte setzen:
| Attributwert | Interpretation |
| normal | Ist der default Wert und macht nichts
besonderes. |
| actual | Bedeutet, dass das Item als in Bearbeitung markiert wird.
Im Augenblick ist dies ein roter Rahmen und der Schriftzug "in
Bearbeitung". |
| main | "main" zeigt an, dass in der entsprechenden
IndexGroup
dieses Item einen Hauptbestandteil ist. Diese Kennzeichnung
ist einfach ein fetterer und schwarzer Rahmen. |
4.5.5. Tabellarische IndexGroup - @type='multicolumn'
Es ist ein weiterer Spezialfall der Darstellung hinzugekommen.
IndexItems sollen
nicht nur in Gruppen zusammengefasst dargestellt werden, sondern desgleichen in
Spalten gruppiert
nach Kategorien. Dafür ist eine neue Struktur eingeführt worden.
Eine IndexGroup wird als tabellarisch wie folgt gekennzeichnet
IndexGroup/@type='multicolumn'.
Welche Spalten es gibt wird im Tag IndexGroup/IndexGroupColumns
beschrieben.
Jede Spalte IndexGroup/IndexGroupColumns/IndexGroupColumn erhält
einen 'title' der im Tabellenkopf
erscheint und eine 'category' als Schlüssel zum Finden der entsprechenden
Einträge. Ein 'style' Attribut mit
einem generischen HTML-Style ist optional.
- IndexGroup: type='multicolumn', id="XXX" (die
Hauptgruppe)
-
- IndexGroupColumns
-
- IndexGroupColumn: title,
category="AAA", style
- IndexGroupColumn: title,
category="BBB", style
- ...
- IndexGroup: id="Zeile1" (eine Zeile ist eine Zeilengruppe)
- IndexItem: category="BBB"
- IndexItem: category="BBB"
- IndexItem: category="AAA"
- ...
- IndexGroup: id="Zeile2"
- IndexItem: category="BBB"
- IndexItem: category="BBB"
- IndexItem: category="AAA"
- ...
- ...
|
Die Zeilen dieser Tabelle sind mit zusätzlichen
IndexGroup-Tags dargestellt.
Diese müssen wie die Haupt-IndexGroup zwingend das Attribut 'id'
gesetzt haben. Dabei muss
jede Zeilengruppe eine eindeutige ID innerhalb der Hauptgruppe besitzen.
| [Jede Zeile ist eine Zeilengruppe] |
|
Innerhalb der Zeilengruppen stehende IndexItem und deren
enthaltene(!) DocInfo-Tags
können nun in eine Kategorie, d. h., genau einer Spalte erscheinen. Dabei
wird das Attribut 'category' auf den
entsprechenden Wert gesetzt. Passiert das nicht, werden diese Tags ignoriert.
Bei den enthaltenen DocInfo-Tags wird der Titel des umgebenden
IndexItem verwendet.
| [Jede Spalte ist eine der vordefinierten Kategorien] |
4.5.6. IndexGroupRef - Referenz zu externer Indexdatei
Es gibt den Fall, dass externe Indexgruppen, also solche auf anderen Seiten als
der aktuellen Indexseite, auf der aktuellen Indexseite sichtbar gemacht werden
sollen. Dann kann in der aktuellen Indexseite über den Tag
IndexGroupRef einen Verweis auf diese externe Gruppe machen.
Dieser Tag stellt also einen Verweis auf eine Gruppe in einem anderen Indexfile
dar.
Er besitzt nur wenige Attribute.
| src | Hier kann man direkt den Pfad zum externen Indexfile
angeben, aus welchem die Gruppe genommen werden soll. |
| navitem | Der Pfad wird nicht aus @src
genommen, sondern NavItem[@title=$navitem]/@src. Wir holen
ihn also indirekt über das Hauptnavigationsfile. |
| title | Gibt IndexGroup/@title an, durch
welchen die externe Gruppe identifiziert wird. |
| mode | Gibt den Modus an, nach welchem mit der Gruppe
verfahren werden soll. |
Wenn der Modus gleich 'merge' ist, dann wird einfach der Inhalt der externen
Gruppe in den Inhalt der Gruppe übernommen, in welcher die Referenz steht.
Haben wir hingegen den Modus 'copy', dann wird die externe Gruppe dargestellt,
als wenn sie eine normale Gruppe der auf sie verweisenden Indexseite wäre.
4.5.7. IndexItemRef
Analog der Referenz für Indexgruppen gibt es eine Referenz für die einzelnen
Items. Diese externen Items werden aus der externen Indexseite genommen und auf
der auf sie verweisenden Indexseite dargestellt.
| src | Dies ist der Pfad, der zur Identifikation des
Items benutzt wird. Er entspricht IndexItem/@src
oder IndexItem/@origsrc.
|
| navitem | Der Pfad zur
externen Indexseite ist NavItem[@title=$navitem]/@src. Wir holen
ihn also indirekt über das Hauptnavigationsfile. |
4.6. Stylesheets
Die Ordnerstruktur unter xml/xsl gibt schon Auskunft über die Anwendung der
jeweiligen Stylesheets. Die relativen Pfadangaben zum Aufruf von untergeordneten
Stylesheets ist dabei in den Styles fest eingegeben und muss bei Veränderung
der Ordnerstruktur nachgezogen werden.
-
xsl
-
-
html, Stylesheets zum Erzeugen von z.B. dem html <head>
-
css, alles, was mit Cascade Stylesheets zu tun hat.
-
excerpt, für die Erstellung der eigentlichen Exzerpte.
-
index, hier sind die Stylesheets rund um die
Erzeugung und das Prozessieren von Indexseiten.
-
conspect, wie der Name schon sagt alles für die Konspekte.
-
purelist, alles, was mit 'purelist' zu tun hat, wie das Wörterbuch
oder die Termine-Seite ...
-
navbarHier finden sich die Stylesheets zum Erstellen der Build-Files
für die Indexseiten, wie auch des Erstellen der Navigationsbalken und
-menus.
-
-
Eigentlich alle Übersetzungen von XML-Dateien in HTML-Seiten benötigen
mehrere Stylesheets, wobei es ein Hauptstylesheet gibt, der die anderen
intern aufruft. Das ist also ein XSL-interner Mechanismus.
Dabei werden die jeweiligen Ausgaben verschachtelt, also die Tags wie bei einer
Zwiebel ineinander gelegt.
Z.B. Exzerpte werden mit dem excerpt/excerpt.xsl
Stylesheet übersetzt.
Der Rahmen im Zielfile als <html>...</html> wird von diesem
Stylesheet erzeugt. Hier hinein wird mit Hilfe der "html"-Stylesheets eine
weitere Schale gelegt.
4.6.1. html
Hier befinden sich alle Stylesheets, die zumeist seitenbezogene HTML-Tags
erzeugen.
-
htmlhead, erzeugt mit Hilfe des
Abstract-Tags des
Quellfiles den Abschnitt <head>...</head> mit den entsprechenden
'META'-Tags und dem
'title' des resultierenden HTML-Files.
-
htmlfoot, es werden hiermit am Ende des HTML-Files innerhalb des
'html/body'
Zusatzinformationen wie z.B. das letzte Compilierdatum erzeugt.
4.6.2. navbar
An dieser Stelle befinden sich sehr verschiedenartige Stylesheets, die aber alle
etwas mit
dem Strukturfile zu tun haben, z.B. dem zentralen
Naviagationsmenu.
-
navbar, dieser zentrale Stylesheet erzeugt das entsprechende
Navigationsmenu am Anfang jeder Seite (HTML-File), welche direkt über die
Navigation zu erreichen ist. Das betrifft alle Indexseiten, wie auch manche
reine Datenseite.
-
navbar2build kreiert zu einer als Parameter gegebenen
NavGroup im Strukturfile ein ANT-Build-File, mit welchem alle zu
dieser Navigationsgruppe oder Ebene gehörenden Zieldateien gebaut oder kopiert
werden.
-
navber2sidemap kompiliert die als 'sitemap' bezeichnete
Gesamtübersicht aus dem Navigationsfile und den Informationen aus den
Abstracts der entsprechenden XML-Quelldateien.
-
navber2sidetree kompiliert die als 'sitemap' bezeichnete
Gesamtübersicht aus dem Strukturfile und den Informationen aus dem
gesamten Spektrum an vorhandenen Files und erzeugt einen vollständigen Baum
der vorhandenen Datenstruktur der gesamten Website.
-
treeview.head.xsl kapselt die für den
/html/head-Tag bestimmten javascript-Abschnitte für die
Baumdarstellung der Sitemap.
-
treeview.abstract.xsl kapselt die Darstellung eines einzelnen
Files als Blatt oder Knoten in der Baumdarstellung der Sitemap.
4.6.3. css
Bisher gibt es nur einen css erzeugenden Stylesheet:
-
maincss.xsl, bildet dateiweite CSS zur HTML-Darstellung, z.B. dass
bei Browseransicht andere Schriftarten als beim Ausdruck zur Anwendung
kommen.
4.6.4. index
Dieser Unterordner enthält sowohl Prozessierungs- als auch
Ansichtsstylesheets für Indexfiles.
-
index.xsl, erzeugt die eigentliche HTML-Repräsentation der
Indexseite.
-
index2index.xsl, bildet eine temporäre XML-Indexseite, welche
alle externen Referenzen und Informationen enthält.
-
index2build.xsl, kompiliert eine XML-Indexseite zu einem
ANT-Build-File, um alle entsprechenden Unterseiten und noch notwendigen
Build-Files erzeugen zu können.
4.6.5. excerpt
Dieser Unterordner enthält sowohl Prozessierungsstyles für
Exzerpte.
-
excerpt.xsl, erzeugt die eigentliche HTML-Repräsentation des
Exzerpts.
-
excerpt.head.xsl, erzeugt die Kopfsektion des Exzerpts mit
allen wichtigen Informationen von und um dieses Dokument.
-
excerpt.head.linklist.xsl, kompiliert eine Tabellenzeile des
Kopfes, in welchem alle Links auf Dokumente platziert sind, die mit
diesem Dokument in Verbindung stehen (siehe
DocInfo).
-
excerpt.content.items.xsl, stellt die eigentlichen Tags, z.B.
P..., des
Exzerptes bzw. verwandter Formen, wie Konspekt, dar.
Hier wird somit der textuelle Inhalt und sein Aussehen selbst erzeugt.
-
excerpt.browser.xsl, dieser spezielle Stylesheet ist für die
Darstellung mittels Browser gedacht und befindet sich im XML-Paket. Hiermit ist
es möglich, sich eigene XML-Files nach unserer DTD anzusehen, ohne den
Prozessierungsmechanismus installieren zu müssen.
4.6.6. Nicht-Indexseiten oder reine Datenseiten
Bei den Nicht-Indexseiten gibt es solche,
- die direkt über die Navigation erreicht werden können und
- solche, die über eine Indexseite zu erreichen sind.
Danach unterscheidet sich natürlich der Aufbau der Seiten. Zur ersten Art
gehören z.B. die Seiten, welche nach 'purelist' als reine Listen aufgebaut
sind. Diese erhalten sowohl ein Navigationsmenu (navbar/navbar.xsl), als auch
eine interne Navigation (titlepopup.xsl und titlepopup.table.xsl).
Als Beispiel sei die Seite 'Aktuell' genommen, welche mit dem Stylesheet
'purelist/purelist.table.xsl' übersetzt wird.
-
purelist.table.xsl, der Hauptstylesheet ruft alle untergeordneten
auf.
Er erzeugt auch den Inhalt der Seite selbst.
-
-
html/htmlhead.xsl, der Kopfbereich der HTML-Seite.
-
navbar/navbar.xsl, das Navigationsmenu
-
titlepopup.xsl, die interne Übersicht über die Liste der
PureListGroups als Popupmenu.
-
html/htmlfoot.xsl, die obligatorischen Zusatzinformationen.
| [Direkt aus dem Hauptmenu zu erreichende Datenseiten] |
|
Die Datenseiten, welche über Indexseiten zu erreichen sind, besitzen kein
Navigationsmenu, dafür aber einen Kopf, welcher nicht mit dem
'html/head' zu verwechseln ist. Im Kopf werden die Informationen aus dem
Abstract, wie 'title', ausgegeben und auch Links zu
zugehörigen Seiten, wie einem Konspekt oder Original, eingefügt. Diese
Informationen sind entweder direkt aus dem IndexItem des
verweisenden Indexfiles oder diesem untergeordneten DocInfo Tags zu
entnehmen.
| [Indirekt - über Indexseiten - zu ereichende Datenseiten] |
Als Beispiel hierfür sei ein Exzerpt genommen, welche mit dem Stylesheet
'excerpt/excerpt.xsl' übersetzt wird.
-
excerpt/excerpt.xsl ist der Hauptstylesheet, der alle
untergeordneten aufruft.
-
-
html/htmlhead.xsl, der Kopfbereich der HTML-Seite.
-
excerpt/excerpt.head.xsl, der Kopfbereich des Exzerptes
-
excerpt/excerpt.head.linklist.xsl, Linkbereich im Kopf
-
excerpt/excerpt.contentitems.xsl, erzeugt den eigentlichen Inhalt
der
Seite selbst, z.B. den HTML-Code der Tags
Cite oder
P.
-
html/htmlfoot.xsl, die obligatorischen Zusatzinformationen.
5. Erzeugen von ANT-Build-Files mit XSL
Da bisher die Struktur der Seite nicht so kompliziert war, wurden die
wichtigsten ANT-Targets von Hand geschrieben.
Es gibt sehr unterschiedliche Targets. Beispielsweise wird mit 'ant news'
angestoßen, dass der Newsletter und der RSS-Newsfeed erzeugt wird. Mit 'ant
main.build' hingegen werden alle Indexseiten des obersten Hauptmenus, sowie
deren direkt enthaltene Unterseiten (im Falle es ist eine Idnexseite) erzeugt.
An dieser Stelle ist noch etwas Arbeit zu investieren.
^
top
last update : Fri Jun 16 20:59:15 CEST 2006 Heilbronn
automatically created by Linux/X86; vendor=Apache Software Foundation; version=1; http://xml.apache.org/xalan-j